metools
Esse é o guia oficial do pacote metools, ele tem como função explicar melhor as funções do pacote e mostrar exemplos de como elas podem ser utilizadas corretamente.
O principal objetivo do pacote metools é facilitar a produção de gráficos e relatórios, mais especificamente para trabalhos macroeconômicos. As funções são dividas em funções graficas e manipuladoras de dados.
Veja abaixo as funções do pacote e suas respectivas divisões:
Manipulação de dados
| cuminyear | Variação acumulada no ano |
| cuminyear_var | Variação acumulada no ano para valores decimais |
| cum_var | Variação acumulada |
| pct_change | Variação percentual em t períodos de uma série |
| num2month | Transforma o nome dos meses em número dos meses |
| month2num | Transforma o número dos meses em nome dos meses |
| me.lag | Atrasa ou adianta um vetor de acordo com o valor de t |
| me.spread | Muda a disposição de um dataframe (long -> wide) |
| stattable | Tabela de estatísticas descritivas |
| col2char | Tranforma as colunas definidas em caractere |
| col2factor | Tranforma as colunas definidas em fator |
| col2num | Tranforma as colunas definidas em número |
| col2percent | Adiciona o símbolo percentual nas colunas definidas |
| colpct2num | Remove o símbolo percentual das colunas definidas, e transforma em número |
| colround | Arredonda as colunas definidas |
| Plot | |
|---|---|
| p.line | Gráfico de linha |
| p.col | Gráfico de colunas |
| p.col_ord | Gráfico de colunas ordenado |
| p.col_ord_wl | Gráfico de colunas ordenado com legenda |
| p.col_wl | Gráfico de colunas com legenda |
| p.tscol | Gráfico de colunas de série temporal |
| p.tsl | Gráfico de linha de série temporal |
| p.gradientcolor | Cria um gradiente |
| p.seqdatebreaks | Cria um intervalo de datas |
| p.colorbypositive | Colore de acordo com o sinal |
| p.colorbyvar | Colore de acordo com a variação |
| mp.s | Plotagem múltipla de séries |
| mp.ts | Plotagem múltipla de séries temporais |
| Modelos gráficos | |
|---|---|
| gm.col | Gráfico de colunas |
| gm.col_ord | Gráfico de colunas ordenado |
| gm.col_ord_wl | Gráfico de colunas ordenado com legenda |
| gm.col_wl | Gráfico de colunas com legenda |
| gm.line | Gráfico de linha |
| gm.tsl | Gráfico de linha de série temporal |
| gm.tscol | Gráfico de colunas de série temporal |
| gm.tscol2 | Gráfico de colunas de série temporal |
Observe que todas as funções da categoria gráfica tem um prefixo,
isso serve para distinguir as funções gráficas das manipuladoras de dados.
Nas próximas sessões serão explicadas cada categoria e suas funções.
Para a aplicação dos exemplos será utilizada uma série temporal do GDP dos Estados Unidos da América(USA), ela foi retirada do ‘World Bank’, para uma execução fidedigna dos exemplos eles estão disponíveis para download clickando aqui. Em alguns exemplos serão utilizados codigos da preparação desse guia, devido a similaridade com a preparação de um relatório, já que foi feito em R Markdown.
Funções manipuladoras de dados
As funções manipuladoras de dados não tem um prefixo definido, boa parte dessas funções trabalham com data.frames, algumas exceções devem ser trabalhadas com vetor. Veja abaixo cada uma das funções manipuladoras de dados detalhadamente.
col2char
A função col2char recebe um objeto dataframe em seu parâmetro x e retorna um novo dataframe com as colunas definidas entre o parâmetro ‘start’ e ‘end’ na classe caractére.
col2char(x,start,end)
x: objeto dataframe
start: número da coluna inicial
end: número da coluna final
Transformações de classe em um dataframe podem exigir um número considerável de linhas de codigo, especialmente quando se é iniciante na programação. A função col2char busca solucionar esse problema. Para criar esse guia foi necessário algumas transformações no dataframe da tabela de funções, mesmo sendo um exemplo simples e pequeno, demonstra bem a utilidade dessa função.
# Utilizando as funções base do R
mp_functions[[1]]=as.character(mp_functions[[1]])
mp_functions[[2]]=as.character(mp_functions[[2]])
plot_functions[[1]]=as.character(plot_functions[[1]])
plot_functions[[2]]=as.character(plot_functions[[2]])
# Utilizando a função col2char do metools
mp_functions=col2char(mp_functions,start=1)
plot_functions=col2char(plot_functions,start=1)Utilizando as funções base do R são necessárias quatro linhas para transformar duas colunas de dois dataframes, utilizando a função col2char o número de linhas se reduz pela metade. Isso é importante, porque muitas vezes dataframes contém mais de dez colunas.
col2factor
A função col2factor recebe um objeto dataframe em seu parâmetro x e retorna um novo dataframe com as colunas definidas entre o parâmetro ‘start’ e ‘end’ na classe factor.
col2factor(x,start,end)
x: objeto dataframe
start: número da coluna inicial
end: número da coluna final
#Transformando a coluna data em factor
usagdp=col2factor(usagdp,start=1,end=1)
usagdp## Date GDP..current.US.. GDP.growth..annual...
## 1 2010-01-01 14.99205 2.563767
## 2 2011-01-01 15.54258 1.550836
## 3 2012-01-01 16.19701 2.249546
## 4 2013-01-01 16.78485 1.842081
## 5 2014-01-01 17.52175 2.451973
## 6 2015-01-01 18.21930 2.880910
## 7 2016-01-01 18.70719 1.567215
## 8 2017-01-01 19.48539 2.217010
## 9 2018-01-01 20.54434 2.927323#Veja os níveis
levels(usagdp[[1]])## [1] "2010-01-01" "2011-01-01" "2012-01-01" "2013-01-01" "2014-01-01"
## [6] "2015-01-01" "2016-01-01" "2017-01-01" "2018-01-01"col2num
A função col2num recebe um objeto dataframe em seu parâmetro x e retorna um novo dataframe com as colunas definidas entre o parâmetro ‘start’ e ‘end’ na classe númerica.
col2num(x,start,end)
x: objeto dataframe
start: número da coluna inicial
end: número da coluna final
#Transform GDP columns in numeric.
usagdp=col2num(usagdp,start=2,end=3)
usagdp## Date GDP..current.US.. GDP.growth..annual...
## 1 2010-01-01 14.99205 2.563767
## 2 2011-01-01 15.54258 1.550836
## 3 2012-01-01 16.19701 2.249546
## 4 2013-01-01 16.78485 1.842081
## 5 2014-01-01 17.52175 2.451973
## 6 2015-01-01 18.21930 2.880910
## 7 2016-01-01 18.70719 1.567215
## 8 2017-01-01 19.48539 2.217010
## 9 2018-01-01 20.54434 2.927323col2percent
A função col2percent recebe um objeto dataframe em seu parâmetro x e retorna um novo dataframe com as colunas definidas entre o parâmetro ‘start’ e ‘end’ na classe caractére mas com o sinal de porcentagem.
col2percent(x,start,end,mult100)
x: um objeto dataframe
start: número da coluna inicial
end: número da coluna final
mult100: se os valores estiverem na forma decimal, use isso para resolver
#Transforma a coluna 'GDP growht' em percentual
usagdp=col2percent(usagdp,start=3,end=3)
usagdp## Date GDP..current.US.. GDP.growth..annual...
## 1 2010-01-01 14.99205 2.56376655876581%
## 2 2011-01-01 15.54258 1.55083550568156%
## 3 2012-01-01 16.19701 2.24954585236992%
## 4 2013-01-01 16.78485 1.84208107101102%
## 5 2014-01-01 17.52175 2.45197303536034%
## 6 2015-01-01 18.21930 2.88091046605219%
## 7 2016-01-01 18.70719 1.56721516997864%
## 8 2017-01-01 19.48539 2.21701033031884%
## 9 2018-01-01 20.54434 2.92732272821085%Se os valores estiverem na forma decimal, você pode utilizar o parâmetro mult100 para resolver isso, veja abaixo:
#Transforma a coluna 'GDP growht' em percentual
usagdp2=col2percent(usagdp,start=3,end=3,mult100=TRUE)
usagdp=cbind(usagdp,"Resultado da função"=usagdp2[,3])
usagdp## Date GDP..current.US.. GDP.growth..annual... Resultado da função
## 1 2010-01-01 14.99205 0.02563767 2.56376655876581%
## 2 2011-01-01 15.54258 0.01550836 1.55083550568156%
## 3 2012-01-01 16.19701 0.02249546 2.24954585236992%
## 4 2013-01-01 16.78485 0.01842081 1.84208107101102%
## 5 2014-01-01 17.52175 0.02451973 2.45197303536034%
## 6 2015-01-01 18.21930 0.02880910 2.88091046605219%
## 7 2016-01-01 18.70719 0.01567215 1.56721516997864%
## 8 2017-01-01 19.48539 0.02217010 2.21701033031884%
## 9 2018-01-01 20.54434 0.02927323 2.92732272821085%colpct2num
colpct2num recebe um objeto dataframe em seu parâmetro x e retorna um novo dataframe com as colunas definidas entre o parâmetro ‘start’ e ‘end’ na classe númerica, utilize essa função para transformar colunas que tem o sinal de porcentagem.
colpct2num(x,start,end,div100)
x: objeto dataframe
start: número da coluna inicial
end: número da coluna final
div100: se precisar do resultado em forma decimal use isso
#Transforma a coluna 'GDP growht' em númerica.
usagdp=colpct2num(usagdp,start=3,end=3,div100=FALSE)
usagdp## Date GDP..current.US.. GDP.growth..annual...
## 1 2010-01-01 14.99205 2.563767
## 2 2011-01-01 15.54258 1.550836
## 3 2012-01-01 16.19701 2.249546
## 4 2013-01-01 16.78485 1.842081
## 5 2014-01-01 17.52175 2.451973
## 6 2015-01-01 18.21930 2.880910
## 7 2016-01-01 18.70719 1.567215
## 8 2017-01-01 19.48539 2.217010
## 9 2018-01-01 20.54434 2.927323Se os valores estiverem na forma inteira, você pode utilizar o parâmetro div100 para resolver isso, veja abaixo:
#Transforma a coluna 'GDP growht' em númerica.
usagdp=colpct2num(usagdp,start=3,end=3,div100=TRUE)
usagdp=cbind(usagdp,"Resultado da função"=usagdp2[,3])
usagdp## Date GDP..current.US.. GDP.growth..annual... Resultado da função
## 1 2010-01-01 14.99205 0.02563767 2.56376655876581%
## 2 2011-01-01 15.54258 0.01550836 1.55083550568156%
## 3 2012-01-01 16.19701 0.02249546 2.24954585236992%
## 4 2013-01-01 16.78485 0.01842081 1.84208107101102%
## 5 2014-01-01 17.52175 0.02451973 2.45197303536034%
## 6 2015-01-01 18.21930 0.02880910 2.88091046605219%
## 7 2016-01-01 18.70719 0.01567215 1.56721516997864%
## 8 2017-01-01 19.48539 0.02217010 2.21701033031884%
## 9 2018-01-01 20.54434 0.02927323 2.92732272821085%colround
A função colround recebe um objeto dataframe no parametro x e retorna um novo dataframe com as colunas definidas entre o parâmetro ‘start’ e ‘end’ com os valores arredondados. Resumindo, essa função arredonda os valores das colunas.
colround(x,start,end,div100)
x: objeto dataframe
start: número da coluna inicial
end: número da coluna final
digits: número de dígitos
#Arredondando as colunas
usagdp=colround(usagdp,start=2,end=3,digits=2)
usagdp## Date GDP..current.US.. GDP.growth..annual...
## 1 2010-01-01 14.99 2.56
## 2 2011-01-01 15.54 1.55
## 3 2012-01-01 16.20 2.25
## 4 2013-01-01 16.78 1.84
## 5 2014-01-01 17.52 2.45
## 6 2015-01-01 18.22 2.88
## 7 2016-01-01 18.71 1.57
## 8 2017-01-01 19.49 2.22
## 9 2018-01-01 20.54 2.93cuminyear
A função cuminyear calcula a variação acumulada no ano de um indíce. Os dados devem iniciar em janeiro, utilize o parâmetro ‘start’ para garantir isso. Se seus dados não iniciarem em janeiro e você necessita usar esses valores, considere completar os meses anteriores com 0.
cuminyear(data,coldate,colnum,start)
data: objeto dataframe
coldate: número da coluna data
colnum: número da coluna valores
start: número da linha inicial
randomts=data.frame("Data"=as.Date(seq.Date(as.Date('2019-01-01'),as.Date('2019-12-01'),'month')),
"Valor"=c(100,110,105,115,118,95,92,100,108,105,110,112)) #Criando uma série temporal aleatória
cuminyear(randomts,coldate = 1,colnum=2,start=1)## [1] 0.00 0.10 0.05 0.15 0.18 -0.05 -0.08 0.00 0.08 0.05 0.10 0.12Como mencionado anteriormente, os dados necessitam iniciar em janeiro, veja abaixo exemplos de como resolver esse problema.
randomts=data.frame("Data"=as.Date(seq.Date(as.Date('2019-04-01'),as.Date('2019-12-01'),'month')),
"Valor"=c(115,118,95,92,100,108,105,110,112)) #Criando uma série temporal aleatória
# Como podemos ver, os dados não iniciam em janeiro, temos duas maneiras de resolver isso:
# primeira -> completar os dados com o primeiro valor:
randomts=merge.data.frame(x=data.frame("Data"=as.Date(seq.Date(as.Date('2019-01-01'),as.Date('2019-03-01'),'month')),"Valor"=rep(randomts[1,2])),y=randomts,all = T)
cuminyear(randomts,coldate = 1,colnum=2,start=1)## [1] 0.00000000 0.00000000 0.00000000 0.00000000 0.02608696 -0.17391304
## [7] -0.20000000 -0.13043478 -0.06086957 -0.08695652 -0.04347826 -0.02608696# segundo -> utilizando o parâmetro 'start' para definir a linha para iniciar
# Nesse caso necessitamos que os dados contenham mais de um ano, vejamos em uma nova série.
randomts=data.frame("Data"=as.Date(seq.Date(as.Date('2018-09-01'),as.Date('2019-12-01'),'month')),
"Valor"=c(100,102,96,98,100,110,105,115,118,95,92,100,108,105,110,112))
# agora nós podemos iniciar na terceira linha, em janeiro de 2019.
cuminyear(randomts,coldate = 1,colnum=2,start=5)## [1] NA NA NA NA 0.00 0.10 0.05 0.15 0.18 -0.05 -0.08 0.00
## [13] 0.08 0.05 0.10 0.12cuminyear_var
A função cuminyear_var calcula a variação acumulada no ano de uma taxa, _var significa que os dados necessitam ser uma variação perecentual. Os dados precisam iniciar em janeiro, se seus dados não iniciam em janeiro e você precisa desses valores, considere completar os meses antêriores com 0.
cuminyear_var(data,coldate,colnum,start)
data: objeto dataframe
coldate: número da coluna data
colnum: número da coluna valores
div100: se seus dados percentuais não estiverem representados como inteiros, use isso
randomts=data.frame("Data"=as.Date(seq.Date(as.Date('2019-01-01'),as.Date('2019-12-01'),'month')),
"Valores"=c(0.02,0.06,0.04,-0.06,-0.02,0.01,-0.06,0.03,0.08,0.01,0.05,0.03))
cuminyear_var(randomts,coldate = 1,colnum = 2)## Valores
## 1 0.02000000
## 2 0.08120000
## 3 0.12444800
## 4 0.05698112
## 5 0.03584150
## 6 0.04619991
## 7 -0.01657208
## 8 0.01293076
## 9 0.09396522
## 10 0.10490487
## 11 0.16015011
## 12 0.19495461Como mencionado anteriormente, os dados necessitam iniciar em janeiro, veja abaixo exemplos de como resolver esse problema.
randomts=data.frame("Data"=as.Date(seq.Date(as.Date('2019-04-01'),as.Date('2019-12-01'),'month')),
"Valor"=c(-0.06,-0.02,0.01,-0.06,0.03,0.08,0.01,0.05,0.03))
randomts## Data Valor
## 1 2019-04-01 -0.06
## 2 2019-05-01 -0.02
## 3 2019-06-01 0.01
## 4 2019-07-01 -0.06
## 5 2019-08-01 0.03
## 6 2019-09-01 0.08
## 7 2019-10-01 0.01
## 8 2019-11-01 0.05
## 9 2019-12-01 0.03# Como podemos observar, os dados não iniciam em janeiro, para resolver isso podemos completar os dados com 0.
randomts=merge.data.frame(x=data.frame("Data"=as.Date(seq.Date(as.Date('2019-01-01'),as.Date('2019-03-01'),'month')),"Valor"=rep(0)),y=randomts,all = T)
cuminyear_var(randomts,coldate = 1,colnum=2)## Valor
## 1 0.00000000
## 2 0.00000000
## 3 0.00000000
## 4 -0.06000000
## 5 -0.07880000
## 6 -0.06958800
## 7 -0.12541272
## 8 -0.09917510
## 9 -0.02710911
## 10 -0.01738020
## 11 0.03175079
## 12 0.06270331Se seus dados estão representados como inteiros, o parâmetro div100 deve ser TRUE para se obter os resultados corretos. Veja o parâmetro div100 utilizado no exemplo abaixo:
randomts=data.frame("Data"=as.Date(seq.Date(as.Date('2019-01-01'),as.Date('2019-12-01'),'month')),
"Valor"=c(2,6,4,-6,-2,1,-6,3,8,1,5,3))
cuminyear_var(randomts,coldate = 1,colnum=2,div100=T)## Valor
## 1 0.02000000
## 2 0.08120000
## 3 0.12444800
## 4 0.05698112
## 5 0.03584150
## 6 0.04619991
## 7 -0.01657208
## 8 0.01293076
## 9 0.09396522
## 10 0.10490487
## 11 0.16015011
## 12 0.19495461cum_var
A função cum_var calcula a variação acumulada de uma taxa durante um determinado periodo de tempo, _var significa que os dados devem ser uma variação perecental.
cum_var(data,colnum,t,div100=F)
data: objeto dataframe
colnum: número da coluna valores
t: número de períodos para acumular
div100: se seus dados percentuais estiverem representados como inteiros, use isso
randomts=data.frame("Data"=as.Date(seq.Date(as.Date('2019-01-01'),as.Date('2019-12-01'),'month')),
"Valor"=c(0.02,0.06,0.04,-0.06,-0.02,0.01,-0.06,0.03,0.08,0.01,0.05,0.03))
cum_var(randomts,colnum=2,t=3,div100=F)## Valor
## 1 NA
## 2 NA
## 3 0.124448
## 4 0.036256
## 5 -0.041952
## 6 -0.069588
## 7 -0.069588
## 8 -0.022118
## 9 0.045656
## 10 0.123524
## 11 0.145340
## 12 0.092315Se seus dados estão representados como inteiros, o parâmetro div100 deve ser TRUE para se obter resultados corretos. Veja o parâmetro div100 utilizado no exemplo abaixo:
randomts=data.frame("Data"=as.Date(seq.Date(as.Date('2019-01-01'),as.Date('2019-12-01'),'month')),
"Valor"=c(2,6,4,-6,-2,1,-6,3,8,1,5,3))
cum_var(randomts,colnum=2,t=3,div100=T)## Valor
## 1 NA
## 2 NA
## 3 0.124448
## 4 0.036256
## 5 -0.041952
## 6 -0.069588
## 7 -0.069588
## 8 -0.022118
## 9 0.045656
## 10 0.123524
## 11 0.145340
## 12 0.092315pct_change
A função pct_change calcula a variação percentual em t periodos de uma séria. Essa função pode ser utilizada para calcular a variação acumulada de um indíce, por exemplo, para calcular a variação acumulada em 12 meses defina o parâmetro ‘t’ como 12.
pct_change(data,colnum,t,nafill)
data: objeto dataframe
colnum: número da coluna valores
t: número de periodos para acumular
nafill: defina o valor para filtrar os valores ‘NA’s’ antes do primeiro valor t
pct_change(usagdp,colnum=2,t=3)## GDP..current.US..
## 1 NA
## 2 NA
## 3 NA
## 4 0.1195831
## 5 0.1273383
## 6 0.1248558
## 7 0.1145282
## 8 0.1120692
## 9 0.1276145num2month
A função num2month transforma o número dos meses em nome dos meses.
num2month(date,abbreviate,ptbr)
date: vetor com meses em número
abbreviate: abrevia o nome dos meses no resultado
ptbr: traduz o resultado para português
randomts=data.frame("Mês"=seq(from=1,to=12,by=1),
"Valor"=c(0.02,0.06,0.04,-0.06,-0.02,0.01,-0.06,0.03,0.08,0.01,0.05,0.03))
num2month(randomts[[1]])## [1] "january" "february" "march" "april" "may" "june"
## [7] "july" "august" "september" "october" "november" "december"Utilizando o parâmetro ‘abbreviate’ e substituindo no dataframe temos:
randomts[[1]]=num2month(randomts[[1]],abbreviate=TRUE)
randomts## Mês Valor
## 1 jan 0.02
## 2 feb 0.06
## 3 mar 0.04
## 4 apr -0.06
## 5 may -0.02
## 6 jun 0.01
## 7 jul -0.06
## 8 aug 0.03
## 9 sep 0.08
## 10 oct 0.01
## 11 nov 0.05
## 12 dec 0.03month2num
A função month2num tranforma o nome dos meses em número dos meses.
month2num
date: vetor com nome dos mêses
randomts=data.frame("Mês"=c("january","february","march","april","may","june","july","august","september",
"october","november","december"),
"Valor"=c(0.02,0.06,0.04,-0.06,-0.02,0.01,-0.06,0.03,0.08,0.01,0.05,0.03))
month2num(randomts[[1]])## [1] "01" "02" "03" "04" "05" "06" "07" "08" "09" "10" "11" "12"É possível utilizar os nomes de forma abreviada.
randomts=data.frame("Mês"=c("jan","feb","mar","apr","may","jun","jul","aug","sep",
"oct","nov","dec"),
"Valor"=c(0.02,0.06,0.04,-0.06,-0.02,0.01,-0.06,0.03,0.08,0.01,0.05,0.03))
month2num(randomts[[1]])## [1] "01" "02" "03" "04" "05" "06" "07" "08" "09" "10" "11" "12"me.lag
A função me.lag atrasa um vetor se o parâmetro t for maior que 0 ou adianta um vetor se t menor que 0.
me.lag
x: vetor
t: número de perídos para atrasar (default=1)
nafill: valor para filtrar ‘NA’s’ antes do primeiro valor de t
extrapolate: se TRUE, extrapola os valores excedentes, somente se t>0.
# Utilização simples
me.lag(usagdp[[2]],t=3)## [1] NA NA NA 14.99205 15.54258 16.19701 16.78485 17.52175
## [9] 18.21930# Utilizando com extrapolação
me.lag(usagdp[[2]],t=3,extrapolate = TRUE)## [1] NA NA NA 14.99205 15.54258 16.19701 16.78485 17.52175
## [9] 18.21930 18.70719 19.48539 20.54434# Adiantando um vetor
me.lag(usagdp[[2]],t=-3)## [1] 16.78485 17.52175 18.21930 18.70719 19.48539 20.54434 NA NA
## [9] NAme.spread
A função me.spread transforma as colunas em linhas e linhas em colunas.
me.spread
data: objeto dataframe
namenc: número da nova coluna
mode: se os resultados estão incorretos, tente definir esse parâmetro como TRUE
Preparando esse documento foi necessario extrair a série usagdp do Banco Mundial (World Bank), mas os dados deviam se preparados para uma melhor explicação. Durante o processo, após o filtro das variáveis, os dados estavam organizados em formato longo, veja abaixo:
## Series name 2010-01-01 2011-01-01 2012-01-01 2013-01-01 2014-01-01
## 1 GDP (current US$) 14.992053 15.542581 16.197007 16.784849 17.521747
## 2 GDP growth (annual %) 2.563767 1.550836 2.249546 1.842081 2.451973A função me.spread pode resolver esse problema. Veja como utilizar a função e o resultado:
me.spread(usagdp_old)## GDP (current US$) GDP growth (annual %)
## 1 2010-01-01 14.992052727 2.56376655876581
## 2 2011-01-01 15.542581104 1.55083550568156
## 3 2012-01-01 16.197007349 2.24954585236992
## 4 2013-01-01 16.78484919 1.84208107101102
## 5 2014-01-01 17.521746534 2.45197303536034Se quiser retornar ao formato anterior basta utilizar a função novamente.
stattable
A função stattable cria uma tabela com estatísticas descritivas.
stattable
data: objeto dataframe
horiz: se TRUE, o resultado será um dataframe na horizontal
mode: se os resultados estiverem incorretos, tente definir esse parâmetro como TRUE
Se seus dados são uma série temporal, não use a coluna com as datas no parâmetro ‘data’, para fazer isso use colchetes ([linha,coluna]) como no exemplo abaixo.
stattable(usagdp[,2:3])## # A tibble: 6 x 3
## Statistic GDP..current.US.. GDP.growth..annual...
## <chr> <dbl> <dbl>
## 1 "Min. " 15.0 1.55
## 2 "1st Qu." 16.2 1.84
## 3 "Median " 17.5 2.25
## 4 "Mean " 17.6 2.25
## 5 "3rd Qu." 18.7 2.56
## 6 "Max. " 20.5 2.93Funções de modelos gráficos
As funções de modelos gráficos tem como objetivo facilitar a criação de gráficos, ela é recomendada para novos programadores, eles têm parâmetros mais fáceis e em menor número do que as funções plot, mas a personalização gráfica é mais limitada. A maneira mais simples de criar gráficos com o pacote metools é usar as funções de modelos gráficos, essas funções usam as funções de plot (do metools) para obter argumentos simplificados; usando essas funções, teremos uma criação de gráficos mais fácil, porém mais limitada.
gm.col
gm.col cria um gráfico de colunas.
gm.col
data : objeto dataframe
ncolx: número da coluna x no dataframe
ncoly: número da coluna y no dataframe
ntimes: número de observações a serem plotadas (contagem por tail)
title: título do gráfico
xlab: título do eixo x
ylab: título do eixo y
div100: se o dado em porcentagem não estiver no formato decimal, defina TRUE.
percent: se TRUE, eixo y em porcentagem
fontsize: altera o tamanho de todas as palavras no gráfico (apenas números)
cserie: muda a cor da série
clines: cor das linhas do gráficos
ctext: cor das palavras do gráficos
cbackground: cor do plano de fundo do gráfico
cbserie: cor da borda da série
randoms=data.frame("Periodo"=letters[1:12],
"Valor"=c(2,6,4,-6,-2,1,-6,3,8,1,5,3))
gm.col(randoms,ncolx = 1,ncoly = 2,ntimes = 8,title = "Metools - gm.col",xlab = NULL,ylab = NULL)
gm.col_ord
gm.col_ord cria um gráfico de colunas ordenado.
gm.col
data : objeto dataframe
ncolx: número da coluna x no dataframe
ncoly: número da coluna y no dataframe
ntimes: número de observações a serem plotadas (contagem por tail)
title: título do gráfico
xlab: título do eixo x
ylab: título do eixo y
percent: se TRUE, eixo y em porcentagem
div100: se o dado em porcentagem não estiver no formato decimal, defina TRUE.
dec: Se TRUE, o gráfico será em ordem decrescente. fontsize: altera o tamanho de todas as palavras no gráfico (apenas números)
cserie: muda a cor da série
clines: cor das linhas do gráficos
ctext: cor das palavras do gráficos
cbackground: cor do plano de fundo do gráfico
cbserie: cor da borda da série
randoms=data.frame("Periodo"=letters[1:12],
"Valor"=c(2,6,4,-6,-2,1,-6,3,8,1,5,3))
gm.col_ord(randoms,ncolx = 1,ncoly = 2,ntimes = 8,title = "Metools - gm.col_ord",xlab = NULL,ylab = NULL,cserie = 'yellow')
Utilizando o argumento ‘dec’ temos:
gm.col_ord(randoms,ncolx = 1,ncoly = 2,ntimes = 8,title = "Metools - gm.col_ord",xlab = NULL,ylab = NULL,cserie = 'yellow',dec=TRUE)
gm.col_ord_wl
gm.col_ord_wl cria um gráfico de colunas ordenado com legenda.
gm.col
data : objeto dataframe
ncolx: número da coluna x no dataframe
ncoly: número da coluna y no dataframe
ntimes: número de observações a serem plotadas (contagem por tail)
title: título do gráfico
legtitle: título da legenda
xlab: título do eixo x
ylab: título do eixo y
percent: se TRUE, eixo y em porcentagem
div100: se o dado em porcentagem não estiver no formato decimal, defina TRUE.
dec: Se TRUE, o gráfico será em ordem decrescente. fontsize: altera o tamanho de todas as palavras no gráfico (apenas números)
colors: cor das barras (um vetor com a cor de cada barra)
clines: cor das linhas do gráficos
ctext: cor das palavras do gráficos
cbackground: cor do plano de fundo do gráfico
cbserie: cor da borda da série
legwpos: posição das palavras da legenda (número)
legheight: altura da legenda
randoms=data.frame("Periodo"=letters[1:12],
"Valor"=c(2,6,4,-6,-2,1,-6,3,8,1,5,3))
gm.col_ord_wl(randoms,ncolx = 1,ncoly = 2,ntimes = 5,title = "Metools - gm.col_ord_wl",legtitle = NULL,xlab = NULL,ylab = NULL,legwpos = -2.5)
gm.col_wl
gm.col_wl cria um gráfico de colunas com legenda.
gm.col
data : objeto dataframe
ncolx: número da coluna x no dataframe
ncoly: número da coluna y no dataframe
ntimes: número de observações a serem plotadas (contagem por tail)
title: título do gráfico
legtitle: título da legenda
xlab: título do eixo x
ylab: título do eixo y
div100: se o dado em porcentagem não estiver no formato decimal, defina TRUE.
percent: se TRUE, eixo y em porcentagem
fontsize: altera o tamanho de todas as palavras no gráfico (apenas números)
colors: cor das barras (um vetor com a cor de cada barra)
clines: cor das linhas do gráficos
ctext: cor das palavras do gráficos
cbackground: cor do plano de fundo do gráfico
cbserie: cor da borda da série
legwpos: posição das palavras da legenda (número)
legheight: altura da legenda
randoms=data.frame("Periodo"=letters[1:12],
"Valor"=c(2,6,4,-6,-2,1,-6,3,8,1,5,3))
gm.col_wl(randoms,ncolx = 1,ncoly = 2,ntimes = 5,title = "Metools - gm.col_wl",legtitle = NULL,xlab = NULL,ylab = NULL,legwpos = -2.5)
gm.tscol
gm.tscol cria um gráfico de colunas com formato de série temporal. Os dados não precisam ser um objeto ts.
gm.tscol
data : objeto dataframe
ncolx: número da coluna x no dataframe
ncoly: número da coluna y no dataframe
ntimes: número de observações a serem plotadas (contagem por tail)
title: título do gráfico
ylab: título do eixo y
percent: se TRUE, eixo y em porcentagem
div100: se o dado em porcentagem não estiver no formato decimal, defina TRUE.
fontsize: altera o tamanho de todas as palavras no gráfico (apenas números)
datebreaks: intervalo entre as datas no eixo x (default=“1 month”)
dateformat: formato da data no eixo x (string com formato de data) (default =“%Y-%m”)
clines: cor das linhas do gráficos
ctext: cor das palavras do gráficos
cbackground: cor do plano de fundo do gráfico
cbserie: cor da borda da série
gm.tscol(usagdp,ncolx = 1,ncoly = 3,ntimes=12,title = "Metools - gm.tscol",datebreaks = "1 year",ylab = NULL,percent = TRUE,div100 = TRUE)
gm.tscol2
gm.tscol2 cria um gráfico de colunas com formato de série temporal, a diferença no tscol2 é que é possível escolhar a cor da série. Os dados não precisam ser um objeto ts.
gm.tscol2
data : objeto dataframe
ncolx: número da coluna x no dataframe
ncoly: número da coluna y no dataframe
ntimes: número de observações a serem plotadas (contagem por tail)
title: título do gráfico
ylab: título do eixo y
percent: se TRUE, eixo y em porcentagem
div100: se o dado em porcentagem não estiver no formato decimal, defina TRUE.
fontsize: altera o tamanho de todas as palavras no gráfico (apenas números)
datebreaks: intervalo entre as datas no eixo x (default=“1 month”)
dateformat: formato da data no eixo x (string com formato de data) (default =“%Y-%m”)
cserie: cor da série
clines: cor das linhas do gráficos
ctext: cor das palavras do gráficos
cbackground: cor do plano de fundo do gráfico
cbserie: cor da borda da série
gm.tscol2(usagdp,ncolx = 1,ncoly = 3,ntimes=12,title = "Metools - gm.tscol2",datebreaks = "1 year",ylab = NULL,percent = TRUE,div100 = TRUE,cserie="orange")
gm.line
gm.line cria um gráfico de linha.
gm.line
data : objeto dataframe
ncolx: número da coluna x no dataframe
ncoly: número da coluna y no dataframe
ntimes: número de observações a serem plotadas (contagem por tail)
title: título do gráfico
xlab: título do eixo x
ylab: título do eixo y
div100: se o dado em porcentagem não estiver no formato decimal, defina TRUE.
percent: se TRUE, eixo y em porcentagem
fontsize: altera o tamanho de todas as palavras no gráfico (apenas números)
lwdserie: tamanho da série
cserie: cor da serie
clines: cor das linhas do gráfico
ctext: cor das palavras do gráfico
cbackground: cor do plano de fundo do gráfico
gm.line(usagdp,ncolx = 1,ncoly = 2,ntimes=12,title = "Metools - gm.line",xlab=NULL,ylab = NULL)
gm.tsl
gm.tsl cria um gráfico de linha em formato de série temporal. Os dados nao precisam ser um objeto ts.
gm.tsl
data : objeto dataframe
ncolx: número da coluna x no dataframe
ncoly: número da coluna y no dataframe
ntimes: número de observações a serem plotadas (contagem por tail)
title: título do gráfico
ylab: título do eixo y
percent: se TRUE, eixo y em porcentagem
div100: se o dado em porcentagem não estiver no formato decimal, defina TRUE.
fontsize: altera o tamanho de todas as palavras no gráfico (apenas números)
lwdserie: tamanho da série
datebreaks: intervalo entre as datas no eixo x (default=“1 month”)
dateformat: formato da data no eixo x (string com formato de data) (default =“%Y-%m”)
cserie: cor da serie
clines: cor das linhas do gráficos
ctext: cor das palavras do gráficos
cbackground: cor do plano de fundo do gráfico
gm.tsl(usagdp,ncolx = 1,ncoly = 3,ntimes=12,title = "Metools - gm.tsl",ylab = NULL,percent = TRUE, div100= TRUE,datebreaks = "1 year",dateformat = "%Y",lwdserie = 2)
Funções Plot
As funções de plot são a forma mais completa de criar gráficos utilizando o pacote metools, elas tem um número significativo de parâmetros para uma melhor e mais detalhada customização gráfica. Essas funções iniciam com o prefixo p, isso inclui gráficos de uma série e algumas ferramentas com cores e valores para os eixos. Para criar gráficos de mais de uma série, entre as funções plot existem as funções multi plot, elas tem prefixo mp.
p.line
p.line cria um gráfico de linha.
p.line
data: objeto dataframe
xaxis: dados do eixo x
yaxis: dados do eixo y
ybreaks: número de intervalos do eixo y (padrão = 10)
percent: se TRUE, eixo y em porcentagem (padrão = F)
yaccuracy: arredondamento para o eixo y (padrão = 0.01)
ydecimalmark: y separador decimal (padrão = “.”)
title: título do gráfico
xlab: título do eixo x
ylab: título de eixo y
stitle: subtítulo do gráfico
note: nota de rodapé
ctitles: cor dos títulos (title, xlab, ylab)
cscales: cor das escalas (padrão = mesmos ctitles)
cbgrid: cor do plano de fundo do grid
clgrid: cor das linhas do grid
cplot: cor do plano de fundo da plotagem
cserie: cor da série
cticks: cor dos ticks dos eixos
lwdserie: tamanho da série
pnote: posição da nota (padrão = 1) (apenas números)
cbord: cor da borda da plotagem (padrão = mesma cplot)
titlesize: tamanho do título (padrão = 20) (apenas números)
wordssize: tamanho das palavras (padrão = 12) (apenas números)
snote: tamanho da nota (padrão = 11) (apenas números)
xlim: limite do eixo x (padrão = NULL)
randoms=data.frame("Periodo"=letters[1:12],
"Valor"=c(2,6,4,-6,-2,1,-6,3,8,1,5,3))
p.line(randoms,randoms[[1]],randoms[[2]],title = "Metools - p.line",xlab = NULL,ylab = NULL,note="Com as funções plot podemos adicionar notas")
p.col
p.col cria um gráfico de colunas.
p.col
data: objeto dataframe
xaxis: dados do eixo x
yaxis: dados do eixo y
ybreaks: número de intervalos do eixo y (padrão = 10)
percent: se TRUE, eixo y em porcentagem (padrão = F)
yaccuracy: arredondamento para o eixo y (padrão = 0.01)
ydecimalmark: y separador decimal (padrão = “.”)
title: título do gráfico
xlab: título do eixo x
ylab: título de eixo y
stitle: subtítulo do gráfico
note: nota de rodapé
ctitles: cor dos títulos (title, xlab, ylab)
cscales: cor das escalas (padrão = igual ctitles)
cbgrid: cor do plano de fundo do grid
clgrid: cor das linhas do grid
cplot: cor do plano de fundo da plotagem
cserie: cor da série
cbserie: cor da borda da série (default= igual cserie)
cticks: cor dos ticks dos eixos
lwdserie: tamanho da série
pnote: posição da nota (padrão = 1) (apenas números)
cbord: cor da borda da plotagem (padrão = mesma cplot)
titlesize: tamanho do título (padrão = 20) (apenas números)
wordssize: tamanho das palavras (padrão = 12) (apenas números)
snote: tamanho da nota (padrão = 11) (apenas números)
xlim: limite do eixo x (padrão = NULL)
randoms=data.frame("Periodo"=letters[1:12],
"Valor"=c(2,6,4,-6,-2,1,-6,3,8,1,5,3))
p.line(randoms,randoms[[1]],randoms[[2]],title = "Metools - p.col",xlab = NULL,ylab = NULL,cscales="blue",note="Com as funções plot temos maior possibilidade de customização")
p.col_ord
p.col_ord cria um gráfico de colunas ordenado.
p.col_ord
data: objeto dataframe
xaxis: dados do eixo x
yaxis: dados do eixo y
ybreaks: número de intervalos do eixo y (padrão = 10)
dec: Se TRUE, o gráfico será em ordem decrescente. (default=FALSE)
percent: se TRUE, eixo y em porcentagem (padrão = F)
yaccuracy: arredondamento para o eixo y (padrão = 0.01)
ydecimalmark: y separador decimal (padrão = “.”)
title: título do gráfico
xlab: título do eixo x
ylab: título de eixo y
stitle: subtítulo do gráfico
note: nota de rodapé
ctitles: cor dos títulos (title, xlab, ylab)
cscales: cor das escalas (padrão = mesmos ctitles)
cbgrid: cor do plano de fundo do grid
clgrid: cor das linhas do grid
cplot: cor do plano de fundo da plotagem
cserie: cor da série
cbserie: cor da borda da série (default= igual cserie)
cticks: cor dos ticks dos eixos
lwdserie: tamanho da série
pnote: posição da nota (padrão = 1) (apenas números)
cbord: cor da borda da plotagem (padrão = mesma cplot)
titlesize: tamanho do título (padrão = 20) (apenas números)
wordssize: tamanho das palavras (padrão = 12) (apenas números)
snote: tamanho da nota (padrão = 11) (apenas números)
xlim: limite do eixo x (padrão = NULL)
randoms=data.frame("Periodo"=letters[1:12],
"Valor"=c(2,6,4,-6,-2,1,-6,3,8,1,5,3))
p.col_ord(randoms,randoms[[1]],randoms[[2]],title = "Metools - p.col_ord",xlab = NULL,ylab = NULL,cbserie='blue')
p.col_ord_wl
p.col_ord_wl cria um gráfico de colunas ordenado com legenda.
p.col_ord_wl
data: objeto dataframe
xaxis: dados do eixo x
yaxis: dados do eixo y
ybreaks: número de intervalos do eixo y (padrão = 10)
percent: se TRUE, eixo y em porcentagem (padrão = F)
dec: Se TRUE, o gráfico será em ordem decrescente. yaccuracy: arredondamento para o eixo y (padrão = 0.01)
ydecimalmark: y separador decimal (padrão = “.”)
title: título do gráfico
xlab: título do eixo x
ylab: título de eixo y
stitle: subtítulo do gráfico
note: nota de rodapé
ctitles: cor dos títulos (title, xlab, ylab)
cscales: cor das escalas (padrão = igual ctitles)
cbgrid: cor do plano de fundo do grid
clgrid: cor das linhas do grid
cplot: cor do plano de fundo da plotagem
cbserie: cor da borda da série (default= igual cserie)
cticks: cor dos ticks dos eixos
lwdserie: tamanho da série
legtitle: título da legenda
legsize: tamanho da legenda
cleg: cor da legenda
legheight: altura da legenda
pnote: posição da nota (padrão = 1) (apenas números)
cbord: cor da borda da plotagem (padrão = mesma cplot)
titlesize: tamanho do título (padrão = 20) (apenas números)
wordssize: tamanho das palavras (padrão = 12) (apenas números)
snote: tamanho da nota (padrão = 11) (apenas números)
legpos: posição da legenda (default= right)
legdir: direção da legenda (default=“horizontal”)
legcol: cor do box da legenda
legspa: espaçamento no box da legenda
legvjust: ajuste vertical do box da legenda
colors: cor das barras, necessita do mesmo número de correspondências.
randoms=data.frame("Periodo"=letters[1:12],
"Valor"=c(2,6,4,-6,-2,1,-6,3,8,1,5,3))
p.col_ord_wl(randoms,randoms[[1]],randoms[[2]],title = "Metools - p.col_ord_wl",xlab = NULL,ylab = NULL,legspa = 0.3,legvjust = -0.9,legsize = 12)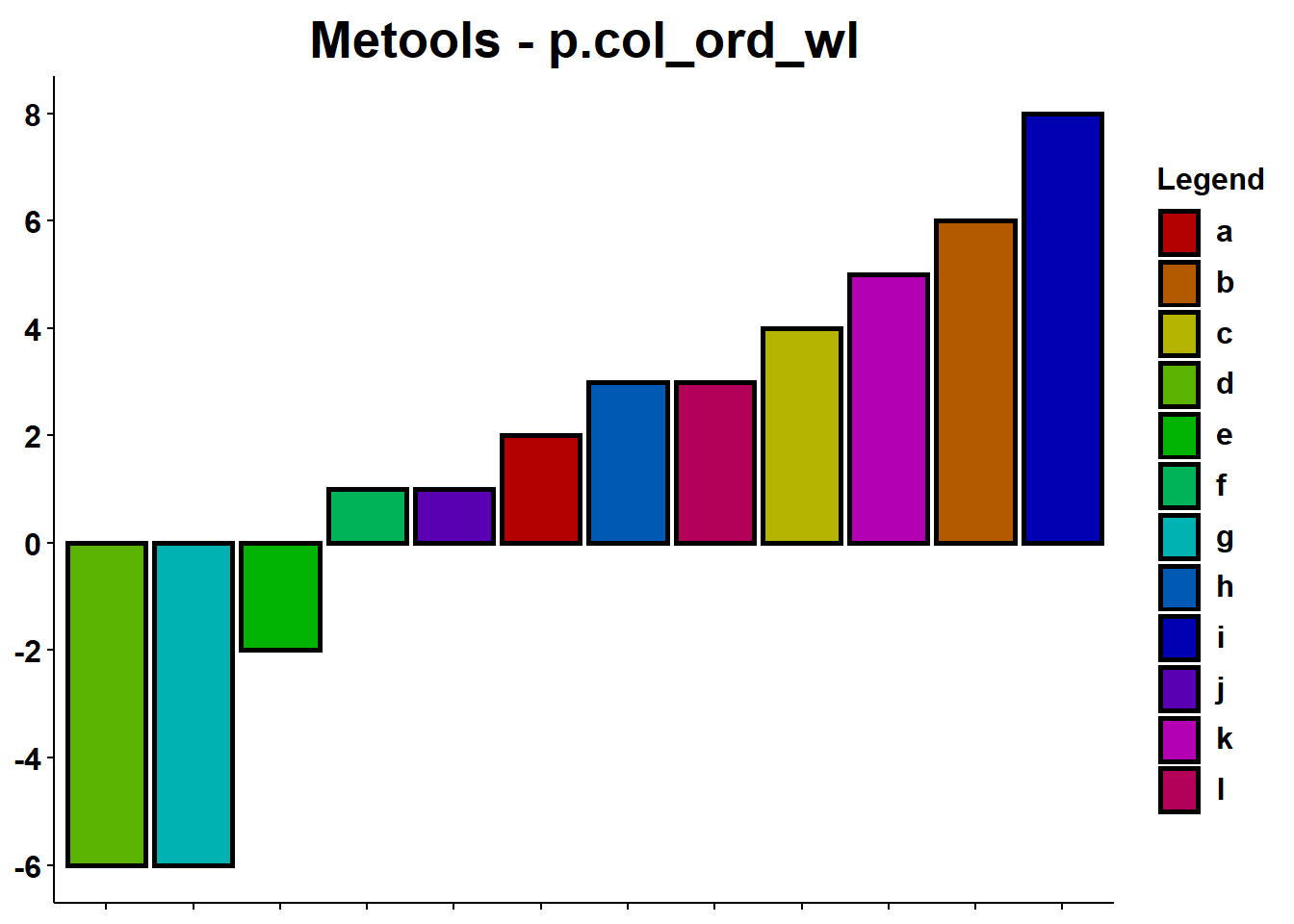
p.col_wl
p.col_wl make a bar plot with legend.
p.col_wl
data: objeto dataframe
xaxis: dados do eixo x
yaxis: dados do eixo y
ybreaks: número de intervalos do eixo y (padrão = 10)
percent: se TRUE, eixo y em porcentagem (padrão = F)
yaccuracy: arredondamento para o eixo y (padrão = 0.01)
ydecimalmark: y separador decimal (padrão = “.”)
title: título do gráfico
xlab: título do eixo x
ylab: título de eixo y
stitle: subtítulo do gráfico
note: nota de rodapé
ctitles: cor dos títulos (title, xlab, ylab)
cscales: cor das escalas (padrão = mesmos ctitles)
cbgrid: cor do plano de fundo do grid
clgrid: cor das linhas do grid
cplot: cor do plano de fundo da plotagem
cserie: cor da série
cbserie: cor da borda da série (default= igual cserie)
cticks: cor dos ticks dos eixos
lwdserie: tamanho da série
legtitle: título da legenda
legsize: tamanho da legenda
cleg: cor da legenda
legheight: altura da legenda
pnote: posição da nota (padrão = 1) (apenas números)
cbord: cor da borda da plotagem (padrão = mesma cplot)
titlesize: tamanho do título (padrão = 20) (apenas números)
wordssize: tamanho das palavras (padrão = 12) (apenas números)
snote: tamanho da nota (padrão = 11) (apenas números)
legpos: posição da legenda (default= right)
legdir: direção da legenda (default=“horizontal”)
legcol: cor do box da legenda
legspa: espaçamento no box da legenda
legvjust: ajuste vertical do box da legenda
colors: cor das barras (um vetor com a cor de cada barra)
randoms=data.frame("Periodo"=letters[1:12],
"Valor"=c(2,6,4,-6,-2,1,-6,3,8,1,5,3))
p.col_wl(randoms,randoms[[1]],randoms[[2]],title = "Metools - p.col_wl",xlab = NULL,ylab = NULL,legspa = 0.3,legvjust = -0.9,legsize = 12)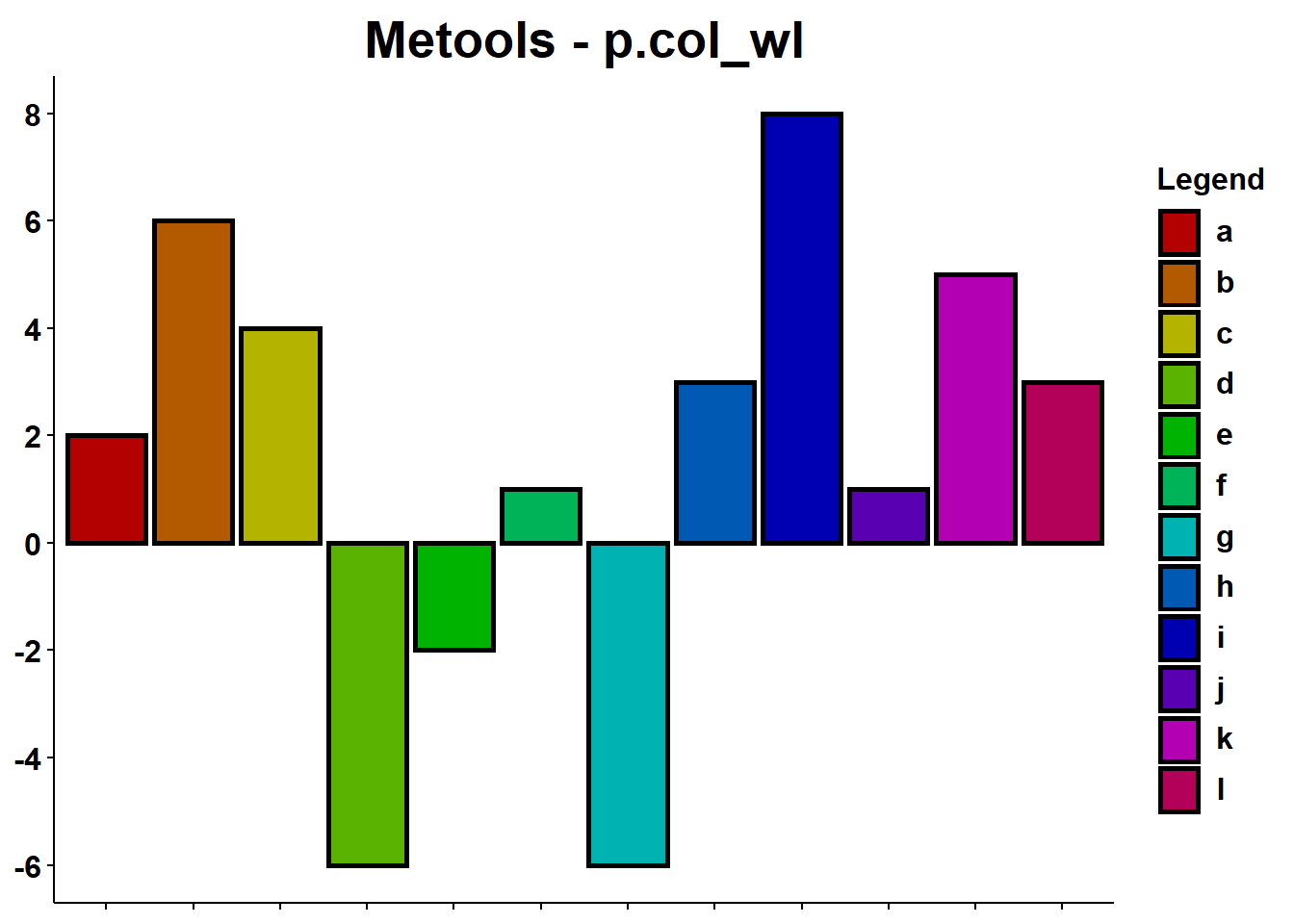
Tanto na função p.col_wl como na p.col_ord_wl é possível alterar a cor das barras, para fazer isso basta alterar o parâmetro ‘color’. Veja no exemplo abaixo:
randoms=data.frame("Periodo"=letters[1:12],
"Valor"=c(2,6,4,-6,-2,1,-6,3,8,1,5,3))
p.col_wl(randoms,randoms[[1]],randoms[[2]],title = "Metools - p.col_wl",xlab = NULL,ylab = NULL,note='A função p.gradientcolor será explicada mais a frente',legspa = 0.3,legvjust = -0.9,legsize = 12,
colors=p.gradientcolor('blue','red',12))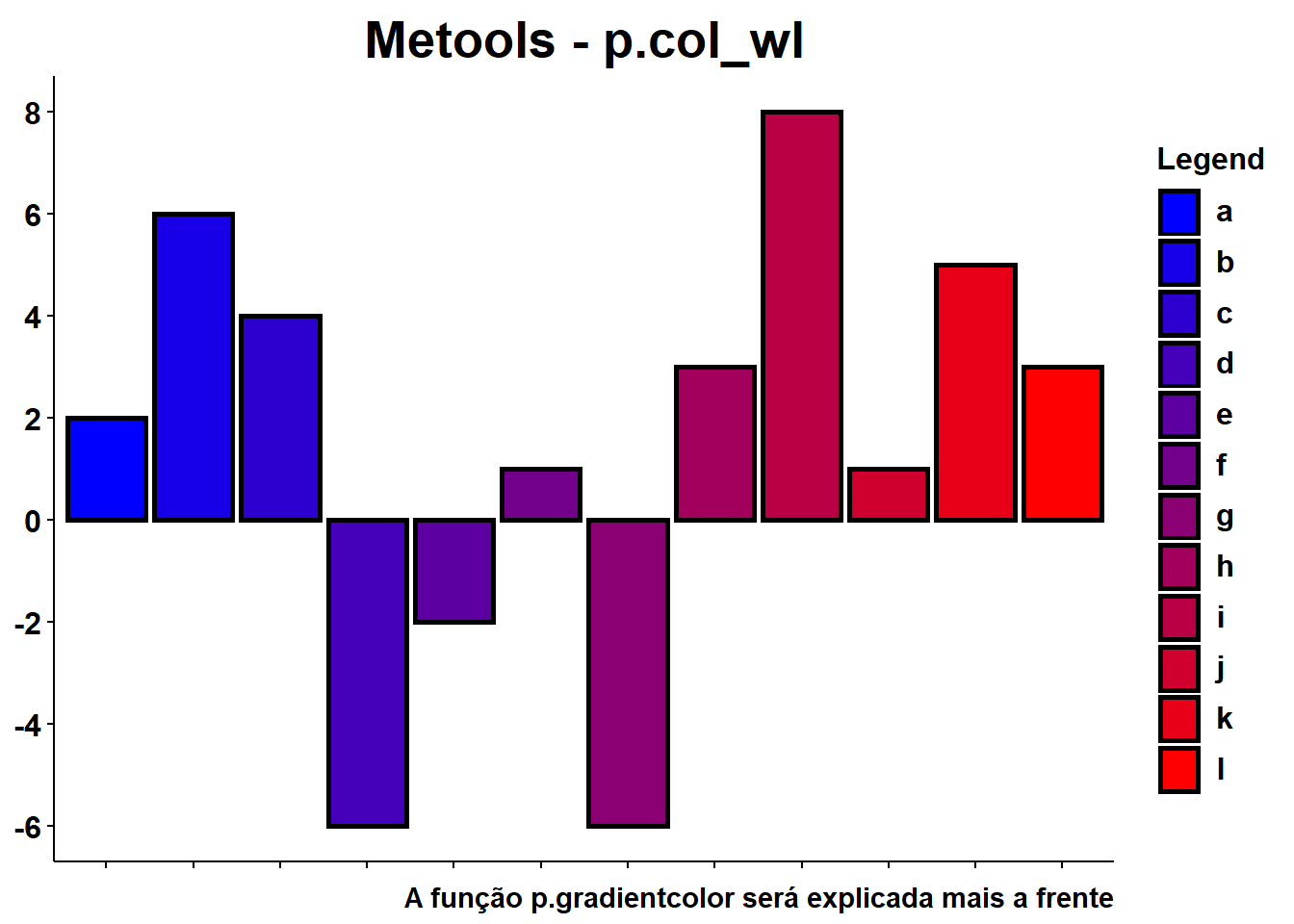
p.tscol
p.tscol cria um gráfico de colunas em formato de série temporal. Os dados não precisam ser um objeto ts.
p.tscol
data: objeto dataframe
xaxis: dados do eixo x
yaxis: dados do eixo y
dateformat: formato da data no eixo x (string com formato de data) (default =“%Y-%m”)
datebreaks: intervalo entre as datas no eixo x (default=“1 month”)
ybreaks: número de intervalos do eixo y (padrão = 10)
percent: se TRUE, eixo y em porcentagem (padrão = F)
yaccuracy: arredondamento para o eixo y (padrão = 0.01)
ydecimalmark: y separador decimal (padrão = “.”)
title: título do gráfico
xlab: título do eixo x
ylab: título de eixo y
stitle: subtítulo do gráfico
note: nota de rodapé
ctitles: cor dos títulos (title, xlab, ylab)
cscales: cor das escalas (padrão = mesmos ctitles)
cbgrid: cor do plano de fundo do grid
clgrid: cor das linhas do grid
cplot: cor do plano de fundo da plotagem
cserie: cor da série
cbserie: cor da borda da série (default= igual cserie)
cticks: cor dos ticks dos eixos
lwdserie: tamanho da série
pnote: posição da nota (padrão = 1) (apenas números)
cbord: cor da borda da plotagem (padrão = mesma cplot)
titlesize: tamanho do título (padrão = 20) (apenas números)
wordssize: tamanho das palavras (padrão = 12) (apenas números)
snote: tamanho da nota (padrão = 11) (apenas números)
xlim: limite do eixo x (padrão = NULL)
p.tscol(usagdp,as.Date(usagdp[[1]]),usagdp[[2]],title = "Metools - p.tscol",xlab = NULL,ylab = NULL,datebreaks = "1 year",dateformat="%Y")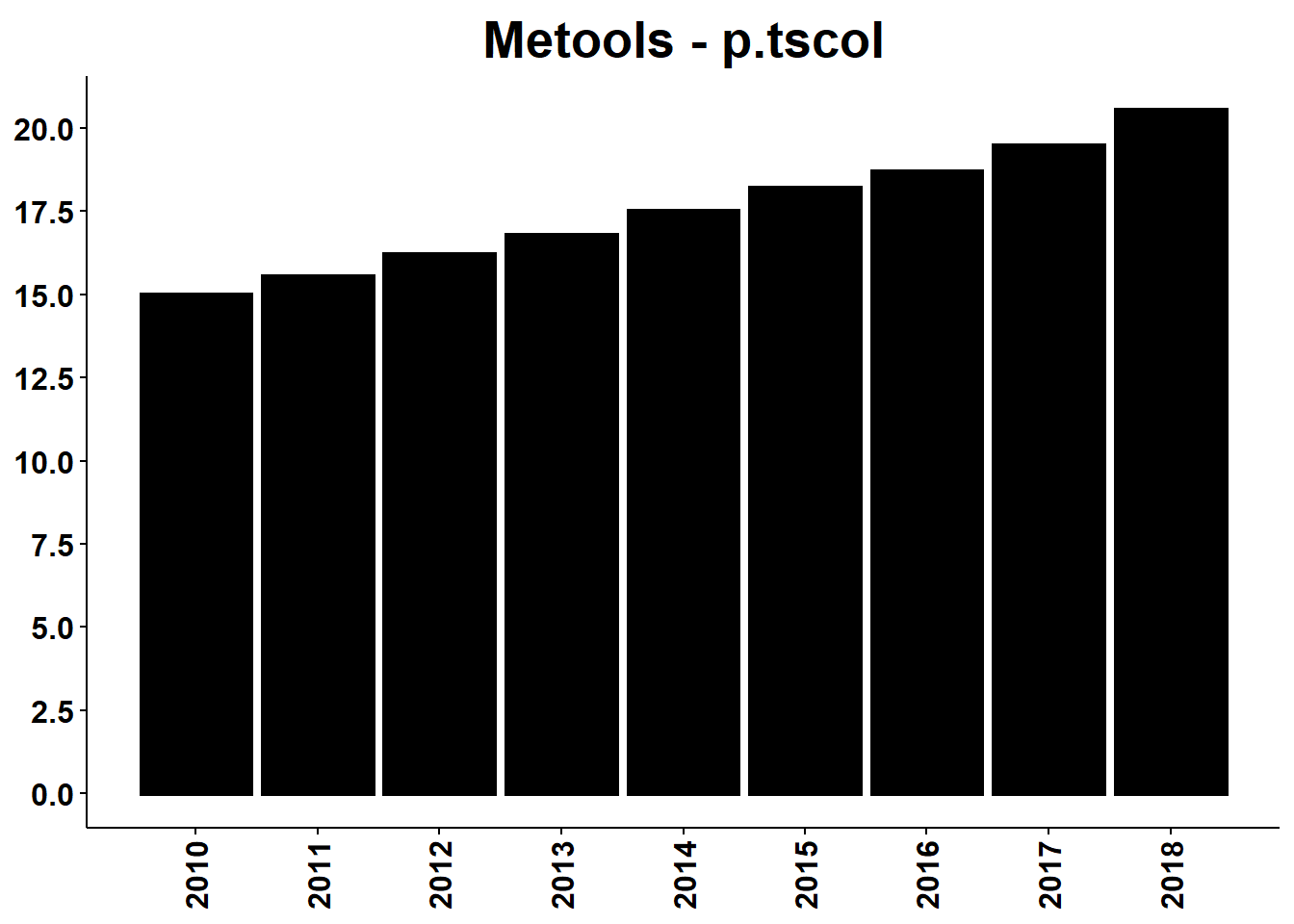
Como a função p.tscol provavelmente será a mais utilizada do pacote, ela será melhor explorada mais a frente.
É importante prestar atenção no parâmetro ‘xaxis’, sua entrada não precisa ser um objeto ts, mas necessita ser um vetor de classe Data. Para garantir que a classe estará correta, você pode utilizar a função as.Date() na entrada do parâmetro ‘xaxis’. Outro parâmetro para prestar atenção é o ‘datebreaks’, se no exemplo anterior não definirmos esse parâmetro como “1 year” , olhe o resultado que seria obtido:
p.tscol(usagdp,as.Date(usagdp[[1]]),usagdp[[2]],title = "Metools - p.tscol",xlab = NULL,ylab = NULL,dateformat="%Y")
Isso ocorre porque o valor padrão do parâmetro ‘datebreaks’ é “1 month”, se a coluna data tivesse a frequência mensal a função teria funcionado normalmente. Então, é importante observar o intervalo entre as datas do seus dados afim de ajustar corretamente ao parâmetro ‘datebreaks’.
p.tsl
p.tsl cria um gráfico de linhas em formato de série temporal. Os dados não necessitam ser um objeto ts.
p.tsl
data: objeto dataframe
xaxis: dados do eixo x
yaxis: dados do eixo y
dateformat: formato da data no eixo x (string com formato de data) (default =“%Y-%m”)
datebreaks: intervalo entre as datas no eixo x (default=“1 month”)
ybreaks: número de intervalos do eixo y (padrão = 10)
percent: se TRUE, eixo y em porcentagem (padrão = F)
yaccuracy: arredondamento para o eixo y (padrão = 0.01)
ydecimalmark: y separador decimal (padrão = “.”)
title: título do gráfico
xlab: título do eixo x
ylab: título de eixo y
stitle: subtítulo do gráfico
note: nota de rodapé
ctitles: cor dos títulos (title, xlab, ylab)
cscales: cor das escalas (padrão = mesmos ctitles)
cbgrid: cor do plano de fundo do grid
clgrid: cor das linhas do grid
cplot: cor do plano de fundo da plotagem
cserie: cor da série
cticks: cor dos ticks dos eixos
lwdserie: tamanho da série
pnote: posição da nota (padrão = 1) (apenas números)
cbord: cor da borda da plotagem (padrão = mesma cplot)
titlesize: tamanho do título (padrão = 20) (apenas números)
wordssize: tamanho das palavras (padrão = 12) (apenas números)
snote: tamanho da nota (padrão = 11) (apenas números)
xlim: limite do eixo x (padrão = NULL)
p.tsl(usagdp,as.Date(usagdp[[1]]),usagdp[[2]],title = "Metools - p.tsl",xlab = NULL,ylab = NULL,datebreaks = "1 year",dateformat="%Y")
Por fim veremos na sequencia as funções ferramentas de plot e funções multiplot. As funções ferramentas de plot tem o mesmo prefixo das funções plot (p.), essas funções tem utilidade sem gráfico, porém, seu objetivo principal é oferecer suporte as função de plot do pacote metools.
p.gradientcolor
A função p.gradientcolor é designada para tornar mais fácil a criação de uma paleta de cores gradiente. Função recomendada para colorir graficos criados com as funções plot do pacote metools.
p.gradientcolor
color1: Primeira cor do gradiente
color2: Ultima cor do gradiente
n: Número de cores
p.gradientcolor(color1="white",color2="blue",n=10)## [1] "#FFFFFF" "#E2E2FF" "#C6C6FF" "#AAAAFF" "#8D8DFF" "#7171FF" "#5555FF"
## [8] "#3838FF" "#1C1CFF" "#0000FF"Usando em um gráfico do metools temos:
p.col_wl(usagdp,format.Date(usagdp[[1]],format="%Y"),usagdp[[2]],xlab=NULL,ylab=NULL,title = "Metools - p.gradientcolor",colors = p.gradientcolor(color1="white",color2="blue",n=10),legspa = 0.25,legvjust = -1.1)
p.seqdatebreaks
A função p.seqdatebreaks é utilizada para separar eixos de data em determinados periodos de tempo. Função recomendada para selecionar intervalos de tempo dos graficos criados com as funções plot do pacote metools.
p.seqdatebreaks
x: Dados temporais de uma série
periodicity: Intervalo de tempo(caractére)
p.seqdatebreaks(x = as.Date(usagdp[[1]]),periodicity = "2 years")## [1] "2010-01-01" "2012-01-01" "2014-01-01" "2016-01-01" "2018-01-01"Essa função é utilizada automaticamente quando você define o parâmetro datebreaks em uma função de plot do metools.
p.colorbypositive
A função p.colorbypositive cria um vetor com cores de acordo com o sinal dos valores. Função recomendada para colorir graficos criados com as funções plot do pacote metools.
p.colorbypositive
x: vetor numérico colorp: Cor dos valores positivos (default=Green)
colorn: Cor dos valores negativos (default=Red)
v=c(-3,-2,2,-2,3,2)
p.colorbypositive(v)## [1] "#B21717" "#B21717" "#17B221" "#B21717" "#17B221" "#17B221"Utilizando em um gráfico metools temos:
randoms=data.frame("tempo"=1:length(v),"valor"=v)
p.col(randoms,randoms[[1]],randoms[[2]],title="Meplot - p.colorbypositive",ylab=NULL,xlab=NULL,cbserie='black',
cserie=p.colorbypositive(v))
p.colorbyvar
A função p.colorbyvar cria um vetor com cores de acordo com a variação dos valores. Função recomendada para colorir graficos criados com as funções plot do pacote metools.
p.colorbyvar
x: a numeric vector colorp: Cor dos valores positivos (default=Green)
colorn: Cor dos valores negativos (default=Red)
lag: Atraso para comparação (default=1)
p.colorbyvar(v)## [1] "#B21717" "#17B221" "#17B221" "#B21717" "#17B221" "#B21717"Utilizando em um gráfico metools temos:
randoms=data.frame("tempo"=1:length(v),"valor"=v)
p.col(randoms,randoms[[1]],randoms[[2]],title="Meplot - p.colorbyvar",ylab=NULL,xlab=NULL,cbserie='black',
cserie=p.colorbyvar(v))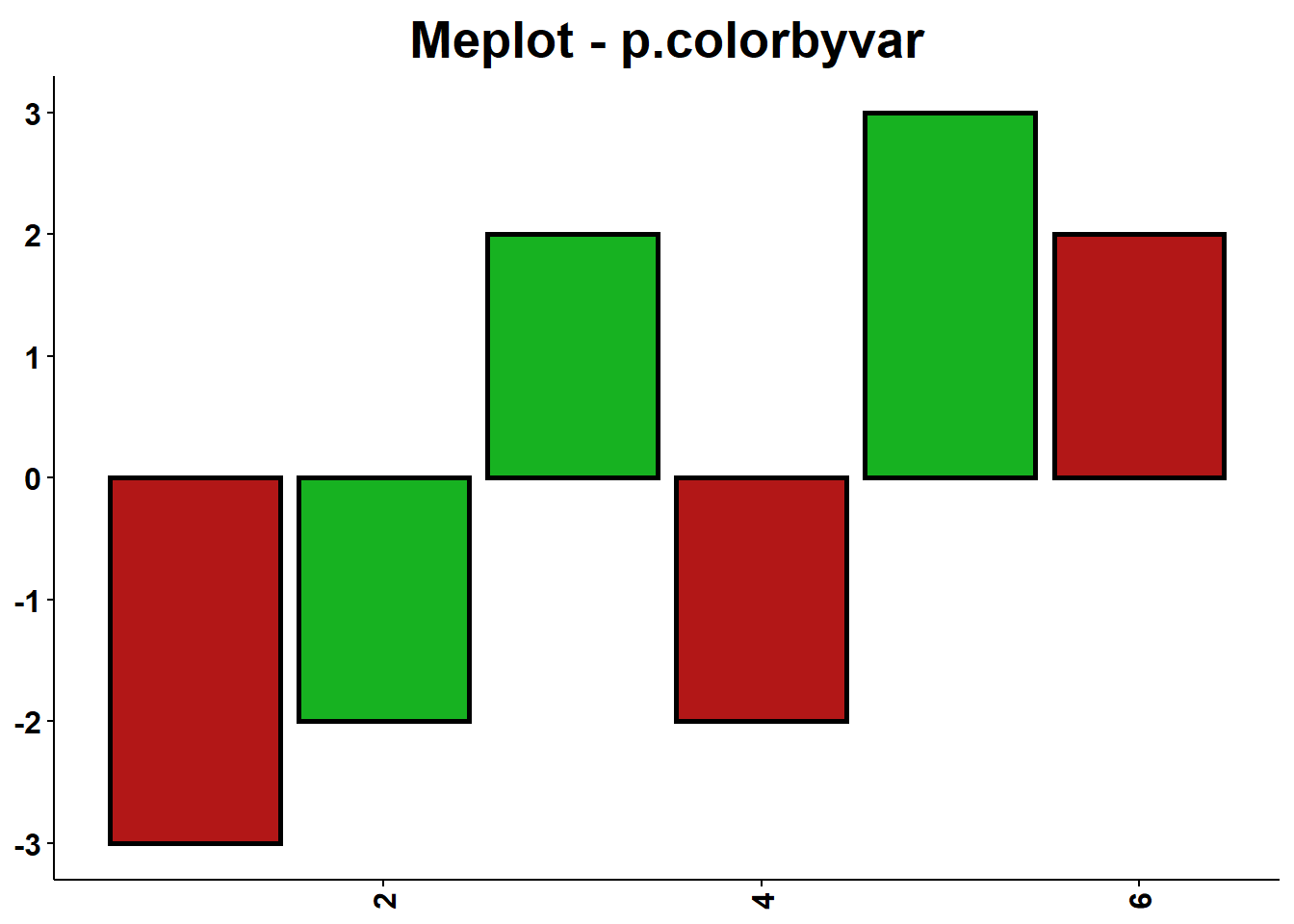
Finalmente chegamos as funções multiplot, essas funções tem o prefixo mp. e basicamente aplicam os parâmetros das funções plot do metools a um objeto ‘ggplot graphic’. Utilize essas função para criar gráficos com mais de uma série.
mp.s
mp.s cria um gráfico com uma ou mais série. O parâmetro ‘object’ requer um objeto ‘ggplot graphic’ (Veja nos exemplos).
mp.s
object: objeto ‘ggplot graphic’
xaxis: eixo x de uma das séries
yaxis: eixo y de uma das séries
ybreaks: número de intervalos do eixo y (padrão = 10)
percent: se TRUE, eixo y em porcentagem (padrão = F)
yaccuracy: arredondamento para o eixo y (padrão = 0.01)
ydecimalmark: y separador decimal (padrão = “.”)
title: título do gráfico
xlab: título do eixo x
ylab: título de eixo y
stitle: subtítulo do gráfico
note: nota de rodapé
ctitles: cor dos títulos (title, xlab, ylab)
cscales: cor das escalas (padrão = mesmos ctitles)
cbgrid: cor do plano de fundo do grid
clgrid: cor das linhas do grid
cplot: cor do plano de fundo da plotagem
cticks: cor dos ticks dos eixos
pnote: posição da nota (padrão = 1) (apenas números)
cbord: cor da borda da plotagem (padrão = mesma cplot)
titlesize: tamanho do título (padrão = 20) (apenas números)
wordssize: tamanho das palavras (padrão = 12) (apenas números)
snote: tamanho da nota (padrão = 11) (apenas números)
xlim: limite do eixo x (padrão = NULL)
randoms=data.frame("Periodo"=letters[1:12],
"V1"=c(2,6,4,-6,-2,1,-6,3,8,1,5,3),
"V2"=c(4,2,-3,-5,-1,5,8,-2,7,3,5,3))
g=ggplot()+geom_line(aes(x=randoms[[1]],y=randoms[[2]],color='blue',group=1),lwd=1.5)+geom_line(aes(x=randoms[[1]],y=randoms[[3]],color='red',group=1),lwd=1.5)
mp.s(g,randoms[[1]],randoms[[3]],title="Metools - mp.s",xlab=NULL,ylab=NULL)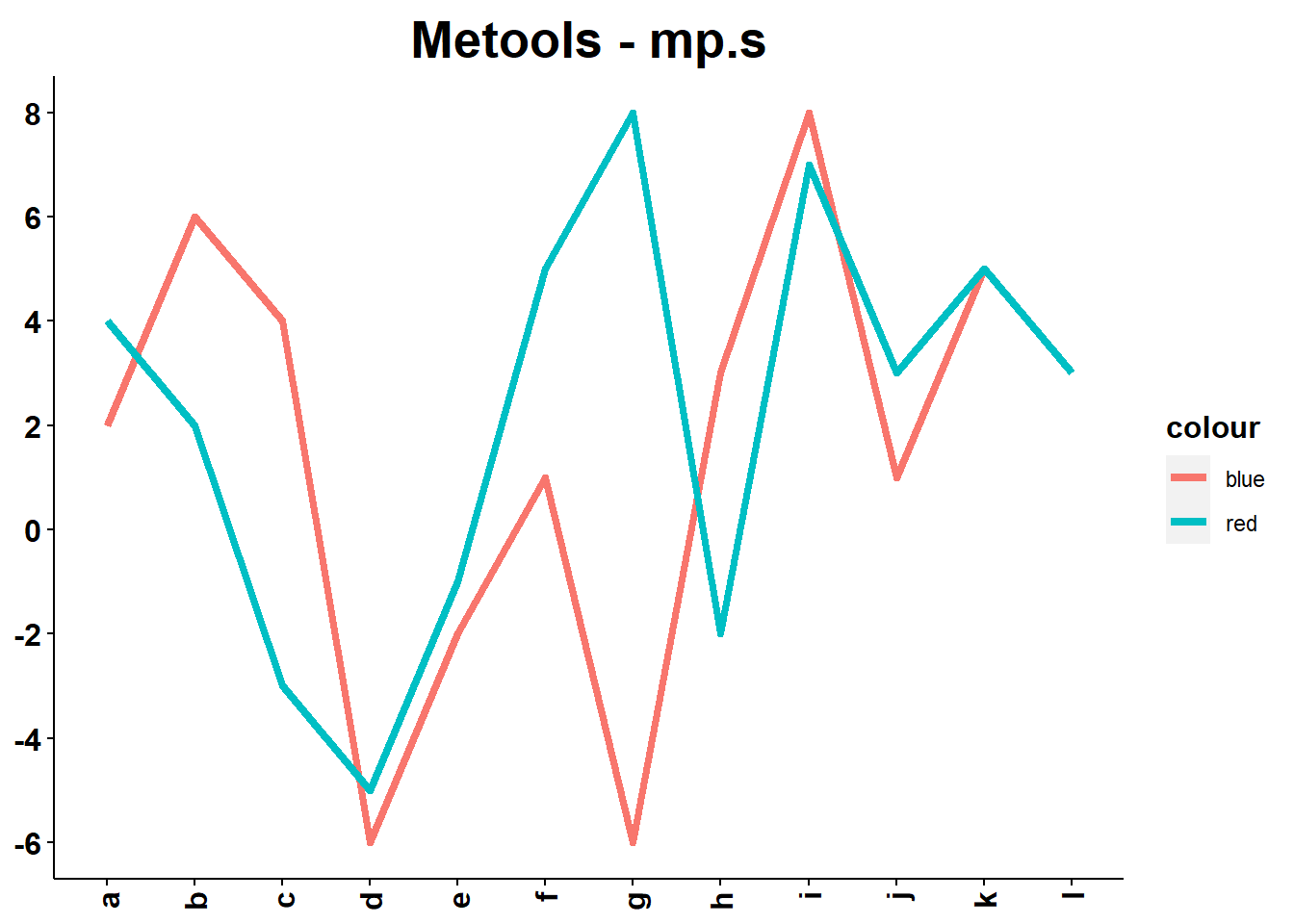
Outros exemplos:
g=ggplot()+geom_col(aes(x=randoms[[1]],y=randoms[[2]],group=1),color='black',fill='black',lwd=1.5)+geom_line(aes(x=randoms[[1]],y=randoms[[3]],group=1),color='red',lwd=1.5)
mp.s(g,randoms[[1]],randoms[[3]],title="Metools - mp.s",xlab=NULL,ylab=NULL)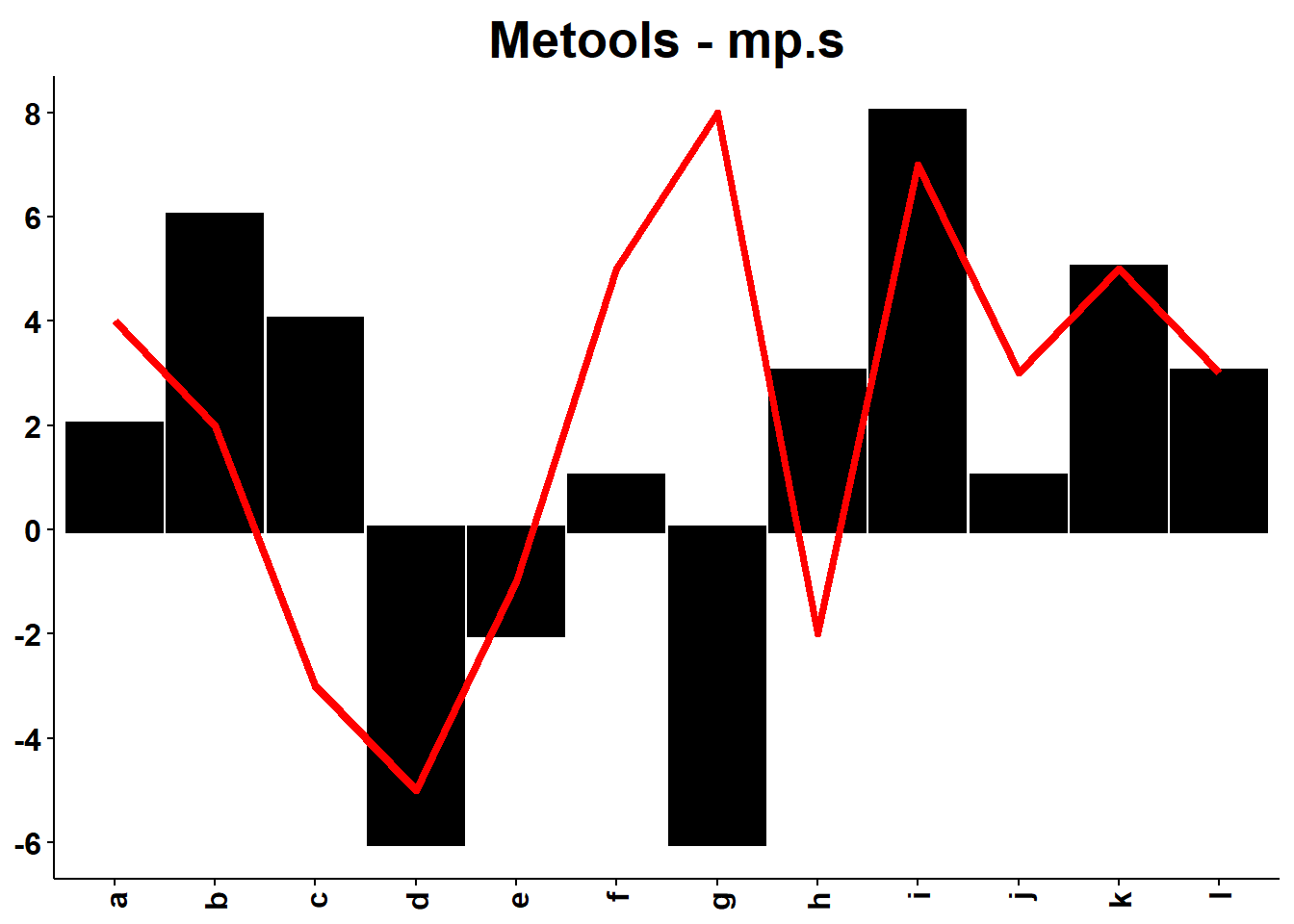
mp.ts
mp.ts cria um gráfico em formato de série temporal com uma ou mais séries. Os dados não necessitam ser um objeto ts. O parâmetro ‘object’ requer um objeto ‘ggplot object’ (Veja nos exemplos).
mp.ts
object: objeto ‘ggplot graphic’
xaxis: eixo x de uma das séries
yaxis: eixo y de uma das séries
dateformat: formato da data no eixo x (string com formato de data) (default =“%Y-%m”)
datebreaks: intervalo entre as datas no eixo x (default=“1 month”)
ybreaks: número de intervalos do eixo y (padrão = 10)
percent: se TRUE, eixo y em porcentagem (padrão = F)
yaccuracy: arredondamento para o eixo y (padrão = 0.01)
ydecimalmark: y separador decimal (padrão = “.”)
title: título do gráfico
xlab: título do eixo x
ylab: título de eixo y
stitle: subtítulo do gráfico
note: nota de rodapé
ctitles: cor dos títulos (title, xlab, ylab)
cscales: cor das escalas (padrão = mesmos ctitles)
cbgrid: cor do plano de fundo do grid
clgrid: cor das linhas do grid
cplot: cor do plano de fundo da plotagem
cticks: cor dos ticks dos eixos
pnote: posição da nota (padrão = 1) (apenas números)
cbord: cor da borda da plotagem (padrão = mesma cplot)
titlesize: tamanho do título (padrão = 20) (apenas números)
wordssize: tamanho das palavras (padrão = 12) (apenas números)
snote: tamanho da nota (padrão = 11) (apenas números)
xlim: limite do eixo x (padrão = NULL)
randoms=data.frame("Data"=seq.Date(as.Date("2019-01-01"),as.Date("2019-12-01"),by='month'),
"V1"=c(2,6,4,-6,-2,1,-6,3,8,1,5,3),
"V2"=c(4,2,-3,-5,-1,5,8,-2,7,3,5,3))
g=ggplot()+geom_line(aes(x=randoms[[1]],y=randoms[[2]],color='blue',group=1),lwd=1.5)+geom_line(aes(x=randoms[[1]],y=randoms[[3]],color='red',group=1),lwd=1.5)
mp.ts(g,randoms[[1]],randoms[[3]],title="Metools - mp.ts",xlab=NULL,ylab=NULL,dateformat="%m/%y")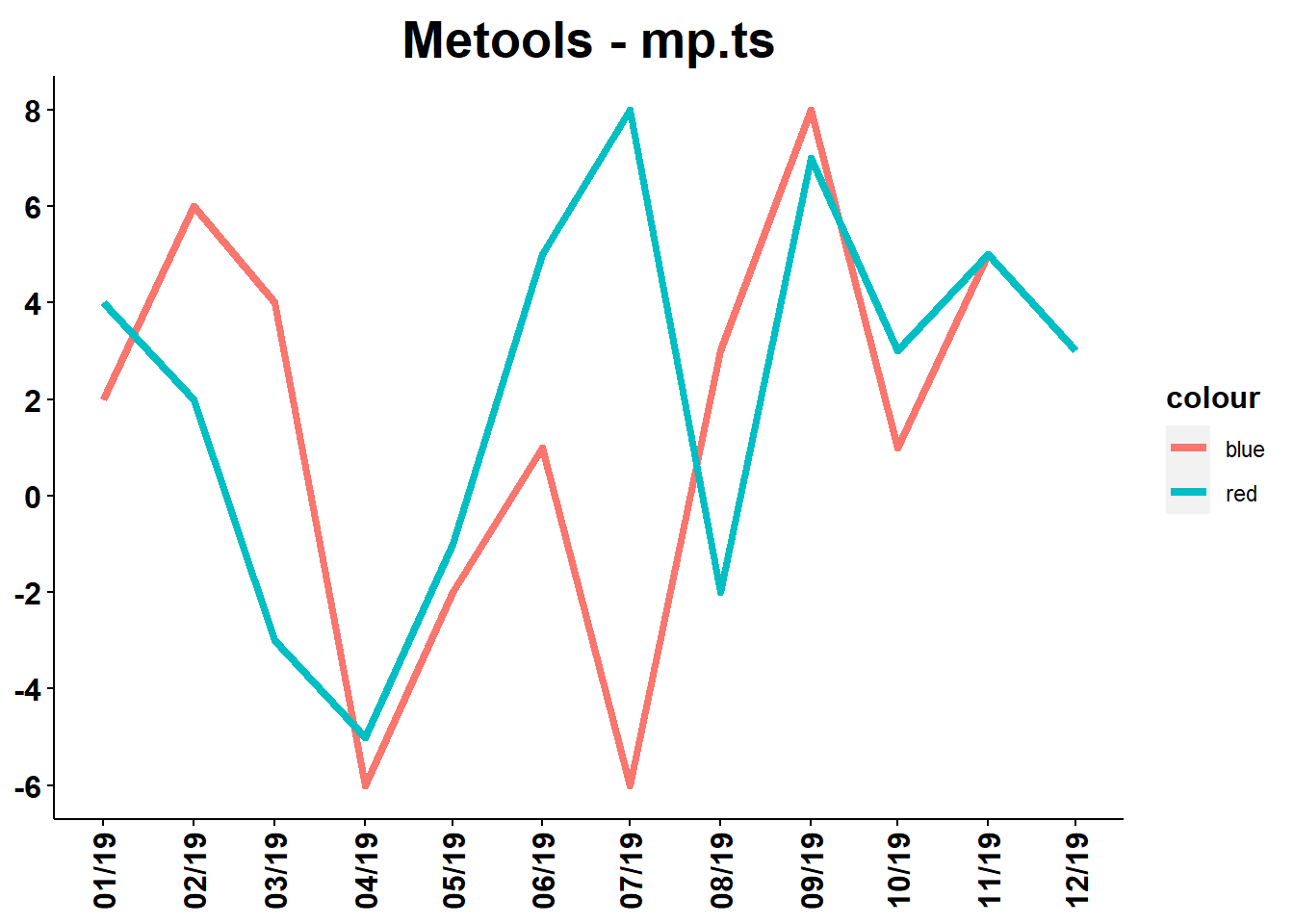
É possível utilizar as funções multiplo para conseguir criar mais tipos de gráficos, o gráfico de área é um exemplo:
randoms=data.frame("Data"=seq.Date(as.Date("2019-01-01"),as.Date("2019-12-01"),by='month'),
"V"=c(2,4,6,3,5,8,6,3,5,4,5,6))
g=ggplot()+geom_area(aes(x=randoms[[1]],y=randoms[[2]],group=1),color='blue',fill='blue',lwd=1.5)
mp.ts(g,randoms[[1]],randoms[[3]],title="Metools - mp.ts",xlab=NULL,ylab=NULL,dateformat = "%b")
Sobre
O pacote metools oferece suporte a preparação de dados e criação de gráficos, prioritariamente a séries temporais e análises/relatórios macroeconômicos.
Para saber mais sobre o pacote metools, acesse o site oficial do pacote: https://metoolsr.wordpress.com/
Guia oficial: https://jvg0mes.github.io/metoolsr
Guia no site: https://metoolsr.wordpress.com/metools/
Download do pacote em tar.gz: https://metoolsr.wordpress.com/download/
Informar erros: https://metoolsr.wordpress.com/contact/